Be you a fan of Elon, or not, I think that the decision to open source the algorithm is a monumental event in social media history.
To-date, we've never seen anything like it. Generally the inner workings and source-code of social media platforms are kept under lock and key and are shrouded in secrecy.
And that for a good reason: it simply wouldn't be in the companies' favor for users to understand how their algorithms work, and what mechanisms are in place to drive interactions, maximize screen-time and keep users engaged for extended periods of time.
Although we're only getting a portion of the entire algorithm, it's surprising to see Elon actually follow through on his plan to open-source the code.
In this post we'll cover everything that we have learned about the algorithm so far, have a look at the technologies that are used throughout the twitter pipeline, as well as the factors that make a good tweet.
I'm quite late to the party as there's already been a number of changes and updates to the code, but let's walk through everything step by step:
Sharing another update on the changes we’ve made to our open source repos this week and a preview of what’s next 🧵https://t.co/sF9ebF0s2X
— Twitter Engineering (@TwitterEng) April 14, 2023
Preamble
Late March of 2022, prior to Elon actually acquiring the site, he posted a poll on the platform itself asking if the source code should be made public:
Twitter algorithm should be open source
— Elon Musk (@elonmusk) March 24, 2022
The poll ended with over 1.1 million votes, where 82.7% percent were in favor of open sourcing the code. This sparked a large debate and many articles were subsequently published on the topic, speculating about the future of the platform and it's implications. Elon himself stated at the time:
I invested in Twitter as I believe in its potential to be the platform for free speech around the globe, and I believe free speech is a societal imperative for a functioning democracy.
After a long back and forth, acquiry of the platform was concluded in October 2022.
It wasn't however until a year later (last month) after making the initial poll, that the algorithm was actually open-sourced and became accessible to the public. And which will be the main topic of discussion of this article. Twitter states:
The goal of our open source endeavor is to provide full transparency to you, our users, about how our systems work.
If you're curious about the Twitter 'Algorithm', but feel that you need just a little bit more context on what an algorithm actually is, then read on. Otherwise you can skip ahead to the sections where we actually discuss the algorithm.
Algorithms are not black magic
What is an Algorithm?
Maybe this is a little bit of a silly question, but if someone asked you, could you give a clear and concise answer to this question? And would your answer be in line with other people's answers?
We live in an age, where algorithms are made out to be like they're some sort of sorcery or black magic. Especially now that a lot of modern softwares incorporate components that make use of ML (Machine Learning) and AI (Artificial Intelligence). In their article on the open-sourcing of the Twitter algorithm, CNN business paints a really blunt picture of what software developers do:
Even those who can understand the code that goes into an algorithm don’t necessarily understand how it works. Consider, for example, how there’s often little more than a basic explanation from tech companies on how their algorithmic systems work and what they’re used for. The people who build these systems don’t always know why they reach their conclusions, which is why they’re commonly referred to as “black boxes.”
This description really bothers me. Makes it seem like software devs don't really know what they do after all, and reinforces the stereotype that programmers just press buttons until things somehow magically work. When we refer to a system as a "black box" it usually means that when we peer inside of it, the internal representations are unintelligible to humans. That doesn't necessarily mean that we don't understand how and why they reach their conclusions.
Fact is, computer code isn't black magic: it's a craft just like any other.
I'm all on board for companies having to explain how their software products work, and have them held to a specific standard of transparency, but it's a two way street. Explaining how code works is often not a straight forward thing to do, simply because there's so many small atomical steps involved that contribute to a larger complex system. It's not that software devs don't know what their system does, it's just not an easy feat to have a complete mental model of such a huge system.
Another recent can of worms that I'm unwilling to open, is the ridiculous TikTok congress hearing. It was a really hard watch, and is just one example of the gigantic disconnect that exists in our world today. If you're a congress-member in session for securing the country's data privacy, you should've at least done your homework and have a basic understanding what an app is and how it works.
And just to be clear, I'm not in any way trying to side with TikTok here. Generally, I'm not a fan of these short-form video content platforms and how most social media platforms are metamorphosing into TikTok clones.
Algorithms and Computer Code

Simply put, an algorithm is a set of instructions that accomplishes a certain task when executed. This instruction set can then be given to the computer to actually complete this particular task. Usually, the coder/programmer/software developer is the person that writes these instructions, in form of computer code and using a specific programming language.
In a very rudimentary manner, programmers are similar to carpenters. Just like a carpenter designs and creates items from wood, that are then assembled into furniture, a programmer drafts and develops computer code that later becomes part of a larger software or system. Both professions require a lot of attention to detail, a slight mistake can have significant consequences down the line.
It's important to note here that a single software often consists of multiple smaller algorithms, each of which solves a particular problem. Just like Santa's little helpers that do all sort of things, from taking care of the reindeers, to assembling the toys.
It's maybe a bit of a stretch to compare an algorithmic system like Twitter's recommendation system to a cookie recipe. A cookie recipe has like what, 5 steps maybe? If you get premade cookie dough then you really just have to put them in the oven and turn on the oven.
The computer is not a smart thing. When you tell a person that they need to mix together the ingredients, they understand the implications; that they first need to get a bowl, then they have to put the individual ingredients in this bowl, then stir until a certain consistency is reached, and so on. The computer does not function in this manner. Writing code requires the programmer to explicitly and meticulously declare all of the individual instructions.
With all of this said, I think we've sufficiently set the scene and are ready to have a look at some parts of the Twitter code and see what they accomplish!
The Recommendation System
Most of the recommendation algorithm will be made open source today. The rest will follow.
— Elon Musk (@elonmusk) March 31, 2023
Acid test is that independent third parties should be able to determine, with reasonable accuracy, what will probably be shown to users.
No doubt, many embarrassing issues will be… https://t.co/41U4oexIev
One portion of the code that has been open-sourced so far constitutes the recommendation system. With the recommendation system we refer to the brain that powers the home-timeline's 'For You Feed'. Twitter's engineering team released a complementary article, where they explain in detail how the this algorithm works. It's actually genuinely super interesting to see the chain of different methods that go into such a pipeline.
c'mon twitter algorithm! daddy needs a new pair of shoes! pic.twitter.com/xrfHFJ3aHz
— Cameron Bradford (@camerobradford) September 22, 2020
In their article they call this recommendation system the home-mixer (as it is named in the source code), which builds your feed whenever you open the home timeline or refresh it. The article uses a fair bit of technical jargon, and does a good job at staying hazy on some points, but I'll try to translate to the best of my ability. One of the best technical recaps I have found on the topic was by Sumit Kumar, which reiterates on the everything but in greater technical detail. Give it a read when you're done here.

In the article they explain that their recommendation pipeline consists of three main stages. We'll have a look at each one in the order that they get invoked whenever the home-mixer gets to work. Although a lot of the methods that are used throughout their pipeline have already been released in form of technical publications, this is the first time that we can see how each component fits into the big picture.
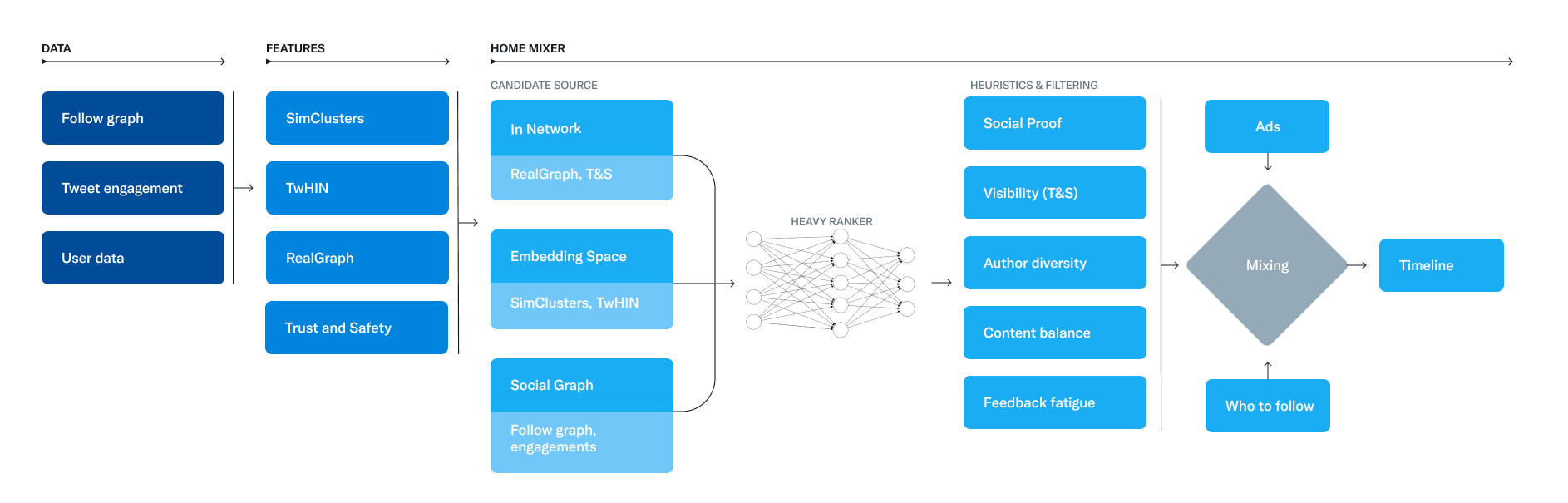
Candidate Sourcing
Candidate Sourcing is the procedure that gathers all of the tweets that could be of interest to a certain user. This is a mix of 1500 tweets from accounts that you follow, as well as accounts that you don't follow. These two sources are labeled as In-Network and Out-of-Network sources respectively.
For most social media platforms it makes sense to represent users internally as a connected graph, where users are represented as nodes and follows are represented by edges between these nodes. Hence the term Network. I'm not entirely certain what the nodes and edges look like and exactly how much data they hold, but there's more than a decade of research behind the data structures and algorithms that power Twitter. Over the years they've released a number of papers for methods that they use internally to traverse and find data on this network. Most notably are the two algorithms RealGraph and GraphJet, which will discuss in this section.
In-Network Sources
To aggregate Tweets from people that one follows, the RealGraph framework is used. RealGraph is a method that can estimate the likehood of a certain user interacting with a certain Tweet based off of a history of previous interactions. The interactions are stored within the directed edges between users.
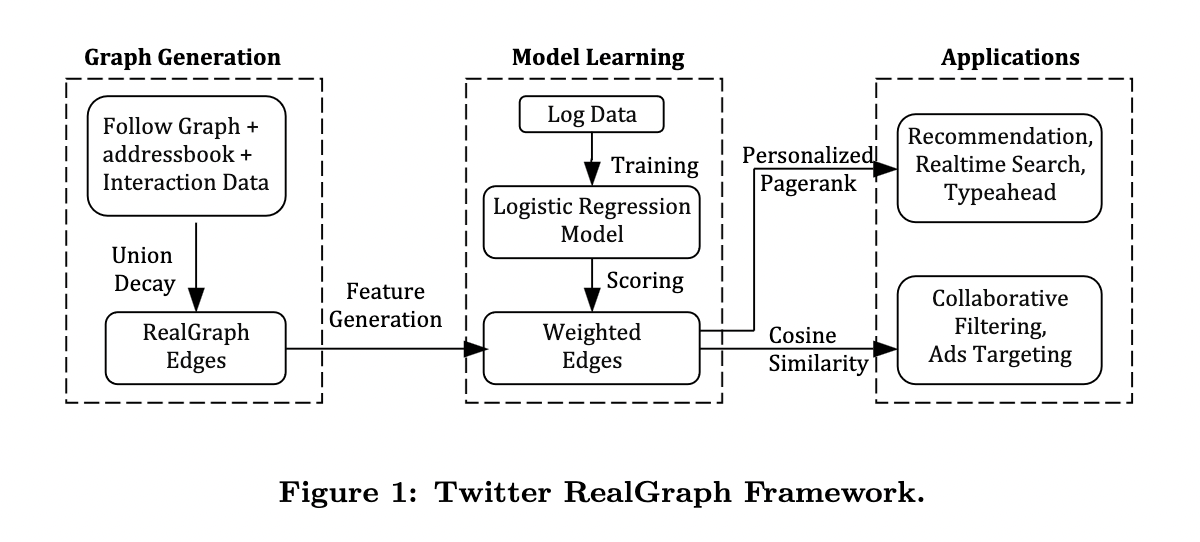
It gets a lot more technical if you have a look at the paper, but essentially this internal graph representation is quite intricate, there's different types of edges depending if the two users follow each other or it's only one directional, or wether they only interact but don't follow each other, etc. And in turn that determines what features get stored on these edges.
This system has probably changed a lot since the paper has been released, but it gives some meaningful insights into how you should be using Twitter if you want to be seen and heard by people: you have to interact with others and incite interactions from them (replies, liking, retweeting, etc.). The network remembers.
Later on, these edge features are then passed to a logistic regression model to estimate if a particular tweet is likely to incite interaction from a user, and thus helps rank the relevancy of these tweets. Logistic regression is essentially a statistical model that can predict the likelihood of something happening given some other information. This part of the pipeline is apparently in the process of being redesigned however.
Sumit Kumar also points out that Twitter makes use of Google's PageRank algorithm to estimate user's overall influence on other users, however I don't fully understand where it fits into the picture. Twitter calls it TweepCred (a tweep is a twitter user, hence short for twitter user credibility).
In the Tweepcred project, the PageRank algorithm is used to determine the influence of Twitter users based on their interactions with other users. The graph is constructed by treating Twitter users as nodes, and their interactions (mentions, retweets, etc.) as edges. The PageRank score of a user represents their influence in the network.
Out-of-Network Sources
To aggregate tweets from sources that a user doesn't follow Twitter makes use of their GraphJet engine.
GraphJet evolved from it's predecessors Cassovary, a previous big graph processing library, as well as their initial user recommendation system WTF (Who to Follow). In addition to the technical details, the GraphJet paper recounts a chronology of previous systems, why they were abandoned, how the system was redesigned from scratch multiple times over and how everything ultimately culminated in the GraphJet engine.
This GraphJet engine can then be used to effectuate a number of different queries, one of which generates a list of tweets that a user might be interested in. Albeit the cornucopium of technical intricacies, the strategy behind the aggregation of such a list is conceptually simple: potentially interesting tweets are found by performing a random walk on the graph.
The catch here is that the 'random walk' through the graph isn't entirely random; there's actually a bunch of rules at play in the background and it's called a SALSA query. Don't bring out the tacos just yet, SALSA stands for Stochastic Approach for Link-Structure Analysis and is another PageRank method that can determine the relevancy of traversed tweets. The special thing about GraphJet is that it can do all of this in real-time, which is an impressive feat considering that 400 billion events have to be processed at any given moment.
Our first approach is to estimate what you would find relevant by analyzing the engagements of people you follow or those with similar interests. We traverse the graph of engagements and follows to answer the following questions:
- What Tweets did the people I follow recently engage with?
- Who likes similar Tweets to me, and what else have they recently liked?
Tweets fetched by this GraphJet query however only make up roughly 15% of the entire 'For You Feed', the majority of the Out-of-Network tweets are collected through another type of representation called SimClusters (Similarity Clusters), which basically refers to groupings of users that share similar interest, the Twitter team describes them as follows:
SimClusters discover communities anchored by a cluster of influential users using a custom matrix factorization algorithm. There are 145k communities, which are updated every three weeks. Users and Tweets are represented in the space of communities, and can belong to multiple communities. Communities range in size from a few thousand users for individual friend groups, to hundreds of millions of users for news or pop culture.
Ranking
Tweet ranking happens via two machine learning models, a light ranker called Earlybird consisting of a logistic regression model and a heavy ranker that is a massive neural network called MaskNet. As their names suggest, the latter is computationally more expensive than the former.
What isn't explained very clearly is where these rankers are employed in the pipeline and in what combination. I assume that the light ranker is used during the search for candidate tweets to evaluate their fitness in the search index, whereas the heavy ranker is used once the list of 1500 candidate tweets has been agregated, filtering out the most relevant ones to be served. However I could be wrong on this one, and apparently it seems that the light-ranker will also be reworked/replaced soon by a newer version.
A detailed resource for this portion of the algorithm is this in depth article by Pasha Kamishev. In his article he dives into the code, reviews specific portions and questions the purpose of different the parts:
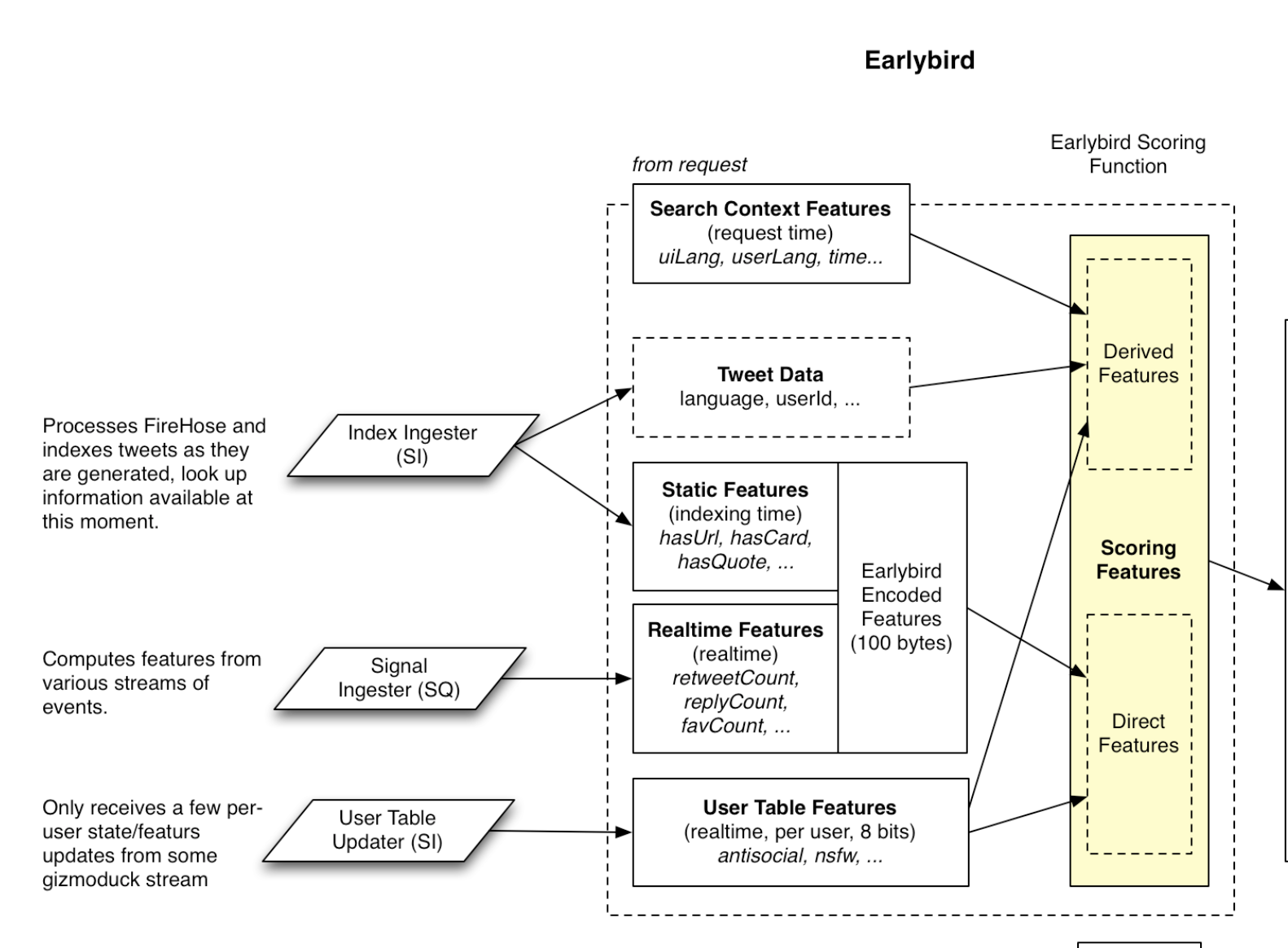
The Light Ranker - Earlybird
The Earlybird light ranker is a logistic regression model which predicts the likelihood that the user will engage with a tweet. It is intended to be a simplified version of the heavy ranker which can run on a greater amount of tweets.
Logistic regression is essentially a statistical model that predicts a binary outcome, such as yes or no. And in this case we are trying to predict whether a given tweet is relevant or not. This prediction is based on the relationship of a number of given independant variables, which in our case are static and real-time tweet features. The static features of a tweet consist of it's language, if it has a link, if it has an image, etc. Real-time features on the other hand are number of likes, retweets, replies, etc.
The Heavy Ranker - MaskNet
The heavy ranker is one of the final stages of the funnel and is explained in the github's readme:
The model receives features describing a Tweet and the user that the Tweet is being recommended to [...]. The model architecture is a parallel MaskNet which outputs a set of numbers between 0 and 1, with each output representing the probability that the user will engage with the tweet in a particular way.
Without going into how neural networks work internally, you can think about them as prediction models that can take one, two or many inputs and then return multiple ouputs as well. In this case we're feeding a bunch of information about the candidate tweet, and a bunch of information about the user that we want to present this tweet to, into the model. The model then spits out a bunch of numbers that estimate the likelihood of the user interacting in different ways with the tweet, which is subsequently combined into a final score. If this final score exceeds a certain threshold the tweet proceeds to the next stage of the pipeline, otherwise it gets discarded.
This model should be fairly accurate as there's plenty of training data already since every little interaction gets recorded by Twitter. Why is it called MaskNet? It's a special type of neural network that has been specifically developed for the purpose of estimating click-through rate, not by Twitter per se, but they adapted a version for their own purposes.
The claims of Twitter's algorithm being a 'black box' are most likely referring to this stage of the pipeline. Neural Networks in general are considered black boxes, not because we don't understand how they work, but because we don't have a good explanation on how they arrive at particular outputs. We are however making progress in this regard with efforts like explainable AI.

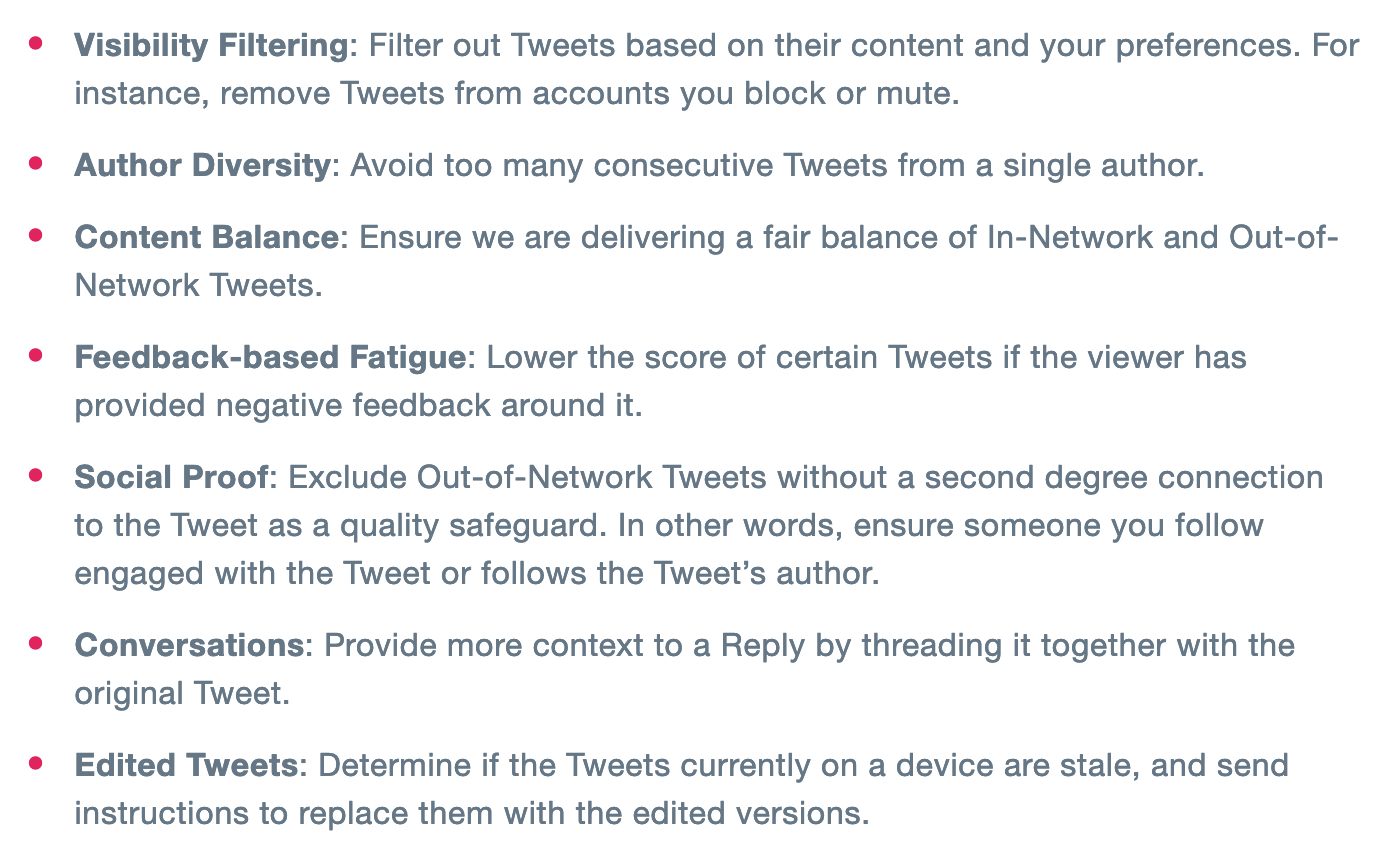
Heuristics and Filtering
The last step in the pipeline is a set of filters that further cleans-up the list of potential tweets that will be served to the viewer:
Naturally we could still talk in much more detail about part of the pipeline, at this point however we've covered the full extent of the Twitter pipeline and all of it's intricacies.
On Tweeting - Discovered Best Practices
Besides revealing how the different components of the pipeline are chained together, the code also gives insight into the factors that affect the ranking of tweets. Factors that us tweeps can influence, and use to our advantage to increase the reach of our tweets.
The different features of a tweet are weighted differently, and can have a drastic effect on whether your tweet will be seen or not. Jacky Chou took a gander at the relevant portion of the code and provides a cheat sheet of best practices:
The Twitter algorithm cheat sheet aka ranking factors for dummies. Bookmark this tweet so you can refer to it later.
— Jacky Chou (buying niche sites up to $1m) (@indexsy) April 1, 2023
Given replies/comments are 1x boost.
Positive factors:
1. Likes, 30x
2. Retweets, 20x
3. Images or videos, 2x
4. English UI (0.5x), tweet (0.2x)
5. Follows… pic.twitter.com/V3HDcHGACK
Overall the biggest influencing factors are likes and retweets which give a massive boost to your tweet's score. This makes me wonder if I should start liking my own tweets immediately as soon as I post them or not? Because that is something that I haven't been doing 🤔
Besides that it's important to provide a complete tweet that has some grammatically correct text, an image, doesn't go overboard with hashtags, doesn't contain a URL etc. It's important to note here that these boosts aren't exactly multiplicative factors:
Don't think so actually, because comments/replies are 1x, wouldn't make sense for it to be 0 impact, especially after my experiment:https://t.co/VkhYNh7K9L
— Jacky Chou (buying niche sites up to $1m) (@indexsy) April 2, 2023
These things might change however in the future depending on community feedback.
10. In the current light ranking model (Earlybird), tweets with images & videos seem to get a nice 2x boost → https://t.co/gbC5sh86MW
— Steven Tey (@steventey) April 1, 2023
However, this is an old model that Twitter is planning to rebuild completely, so things might change → https://t.co/asg23uoh4S pic.twitter.com/hgZXR1xWz5
Aftermath and Implications
What is the aftermath of open-sourcing the Algorithm? What have we actually learned about how Twitter works? A great read for this is a post by The Atlantic:

Many parts of the puzzle are still missing, what we got is a highly redacted version of the code that actually powers Twitter. It is a bit unclear at this point how this will affect the future of the platform, if it will actually incite change or if Twitter will keep doing their own thing behind the curtain. Skepticism remains high among researchers as we're not getting a whole lot to work with:
But none of the code Twitter released tells us much about potential bias or the kind of “behind-the-scenes manipulation” Musk said he wanted to reveal. “It has the flavor of transparency” [...]


This comes alongside changes in the pricing of the API, rendering it unaffordable to many. Independent devs and researchers will no longer be able to use these services:
$100 a month for hobbyists? That's not hobbyist tier pricing, lmao. RIP Twitter.
— Dumpster Fire (@VanFlip10x) March 30, 2023
/cdn.vox-cdn.com/uploads/chorus_asset/file/23926015/acastro_STK050_06.jpg)
It seems that most changes to the platform and it's auxiliary services in the past months have been centered around boosting revenue, rather than being a service to those who use the platform.
Moreover, the snapshot of code that we've been granted access to brings up many ontological question. For instance, a big problematic that I see with ranking tweets is that it clashes with the idea of bolstering free speech, which I thought was the whole point, and that Musk is trying to make the platform all about.
For instance, a tweet that contains a link is ranked lower than an identical one without a link... what's the correlation here? Shouldn't it be more about what it is linking to rather than it including a link? Wouldn't it be better to look at the domain authority of the linked resource rather than condemn the tweet alltogether from the start?
And this problematic is not just limited to the has_link ranking criteria, but applies to the other ones as well. Why should a Twitter Blue user have their tweets boosted and have more reach that way? How does this agree with the idea of free speech?

Concluding Thoughts
Although the open-sourced portion of code gives some insights into the inner workings of Twitter, it is ultimately not certain what other things go on behind the scenes and if this is actually the same code that Twitter uses in production.
Although the tech being cutting-edge and impressive, I have the impression that it is incredibly bloated and convoluted. I have absolutely no idea how they're able to maintain any of it.
No doubt, many embarrassing issues will be discovered. pic.twitter.com/r3rgFJ1HHa
— Ron Pragides (@mrp) April 1, 2023
Additionally, I have concerns about the future of the platform. I use Twitter to communicate with the outside world, and to share my writings, art and creations. Many have already left Twitter in favor of other platforms, like the decentralised Mastodon:

Albeit all of this, I think I will stick around for now and assess once there's new developments. You'll always find me on this blog, so there's no worries about that.
As always, thanks for reading! If you enjoyed reading this post you might also enjoy: